How to Determine Which Clustering Method to Use
How Does Hierarchical Clustering Work. Choose this method to compute a fixed number of clusters.

A Comprehensive Guide On Clustering And Its Different Methods Method Biomedical Predictive Analytics
Here how it looks like.
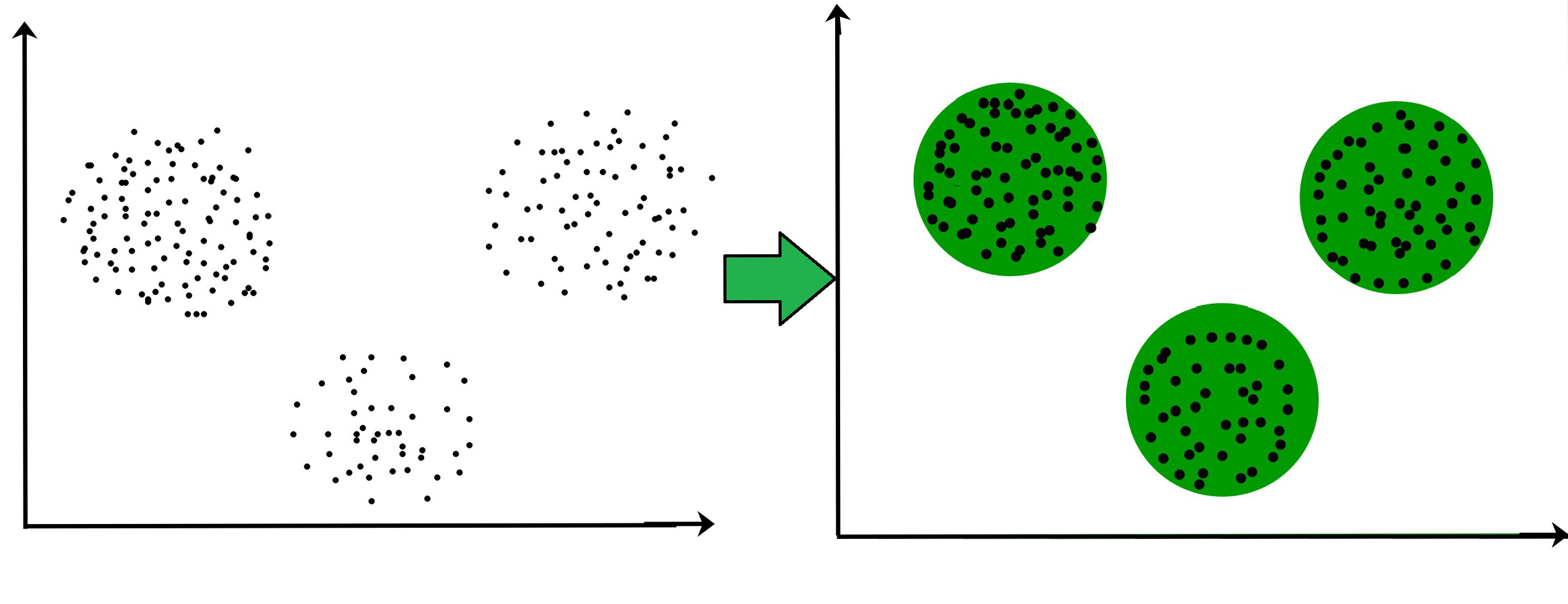
. Two well-known divisive hierarchical clustering methods are Bisecting K-means Karypis and Kumar and Steinbach 2000 and Principal Direction Divisive Partitioning Boley 1998. In single-stage sampling you collect data from every unit within the selected clusters. N is the number of samples within the data set C is the center of a cluster.
So the Inertia simply computes the squared distance of each sample in a cluster to its cluster center and sums them up. This method calls SASSTAT PROC FASTCLUS. Barplothclustheight namesarg nrowX - 11 show the number of cluster below each bars.
We can calculate the gap statistic for each number of clusters using the clusGap function from the cluster package along with a. The R code below computes NbClust for k-means. Many clustering methods use distance measures to determine the similarity.
In all three types you first divide the population into clusters then randomly select clusters for use in your sample. Refer to the PROC FASTCLUS documentation for additional details. Thorndike Psychometrika 18 4.
You just need to run your clustering algorithm multiple times with a different number of clusters and use any metric function we described above. The clusters determined with DBSCAN can have arbitrary shapes thereby are extremely accurate. Consider the below data set which has the values of the data points on a particular graph.
For a certain class of clustering algorithms there is a parameter commonly referred to as k that specifies the number of clusters to detect. You can achieve both methods by using existing SAS procedures and the DATA step. Find the average distance of each point in a cluster to its centroid and represent it in a plot.
Step by step DBSCAN Density-Based Spatial Clustering of Applications with Noise algorithm checks every object changes its status to viewed classifies it to the cluster OR noise until finally the whole dataset is processed. Elbow Method is an empirical method to find the optimal number of clusters for a dataset. For this we try to find the shortest distance between any two data points to form a cluster.
In double-stage sampling you select a. The Automated K Means method is selected by default. In this blog I will go a bit more in detail about the K-means method and explain how we can calculate the distance between centroid and data points to form a cluster.
X dfAge Spending Score 1-100copy The next thing we need to do is determine the number of clusters that we will use. Next lets define the inputs we will use for our K-means clustering algorithm. Y_s new_points 1 Make a scatter plot of x_s and y_s using labels to define the colors.
For every cluster we can calculate its corresponding centroid ie. Equation 1 shows the formula for computing the Inertia value. First you need to choose your metric function.
We can also determine the individual that is the closest to the centroid called the representant. Determining the number of clusters in a data set a quantity often labelled k as in the k-means algorithm is a frequent problem in data clustering and is a distinct issue from the process of actually solving the clustering problem. Calculate the Within-Cluster-Sum of Squared Errors WSS for different values of k and choose the k for which WSS becomes first starts to diminish.
Pltscatter x_sy_sclabelsalpha05 Assign the cluster centers. Such an analysis however is outside of the scope of this paper. Determining The Right Number Of Clusters.
Since clustering is the grouping of similar instancesobjects some sort of measure that can determine whether two objects are similar or dissimilar is required. This was introduced rather amusingly in 1953 by R. Distance measures and similarity measures.
We will use the elbow method which plots the within-cluster-sum-of-squares WCSS versus the. There are two main type of measures used to estimate this relation. X_centroids y_centroids x_centroids.
Methods to determine the number of clusters in a data set Data set. 267-276 and although in that treatise he didnt think. Determining The Right Number Of Clusters.
To compute NbClust for hierarchical clustering method should be one of cwardD wardD2 single complete average. Lets consider that we have a few points on a 2D plane with x-y coordinates. PK C 1C K.
To compute NbClust for kmeans use method kmeans. Lets use age and spending score. Likewise we can also look for the second best representant the third best representant etc.
We want to determine a way to compute the distance between each of these points. In this method we pick a range of candidate values of k then apply K-Means clustering using each of the values of k. We can randomly choose Read More Steps to calculate centroids in cluster using K-means.
Another way to determine the optimal number of clusters is to use a metric known as the gap statistic which compares the total intra-cluster variation for different values of k with their expected values for a distribution with no clustering. Centroids modelcluster_centers_ Assign the columns of centroids. One method that works fairly well although tends to underestimate the actual number of clusters is to look at the within cluster similarity at each stage.
Finally we could also determine the optimal number of cluster thanks to a barplot of the heights stored in height of the clustering output. Here each data point is a cluster of its own. Use the radio buttons to select the method used for joining the clusters.
This method is simple. Hierarchical with given choices of metric and link function or k-means with given choice of metric With method and K clusters we obtain a partition of the points. X i i1N points in R p each coordinate is a feature for the clustering Clustering method.
This process is done for each cluster and all samples within that data set. Then run the clustering algorithm for k 1 2 3.
Data Mining Cluster Analysis Javatpoint
Hierarchical Clustering In Data Mining Geeksforgeeks
Clustering In Machine Learning Algorithms That Every Data Scientist Uses Dataflair

Clustering Algorithm An Overview Sciencedirect Topics

Panel Data Analysis A Survey On Model Based Clustering Of Time Series Analysis Data Analysis Data
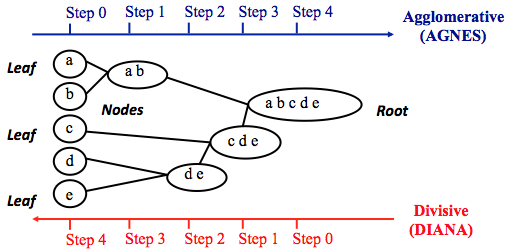
Hierarchical Cluster Analysis Uc Business Analytics R Programming Guide
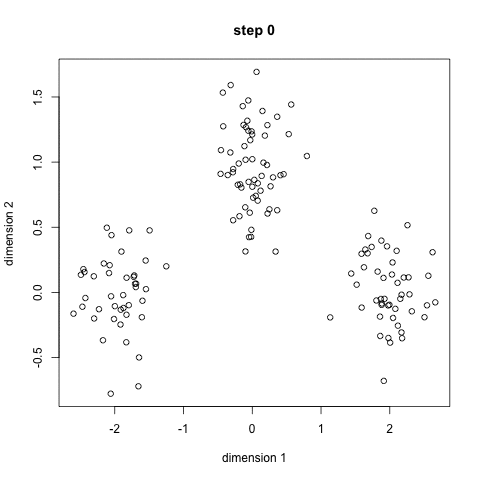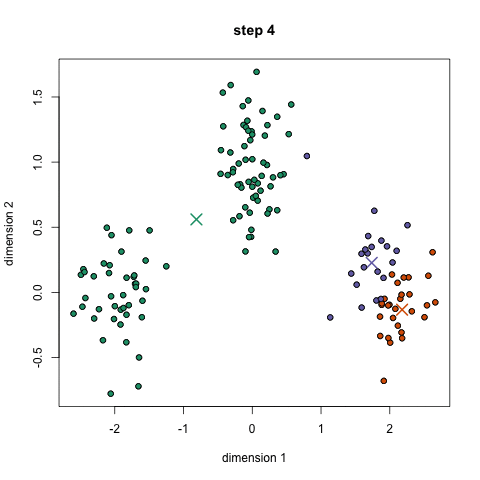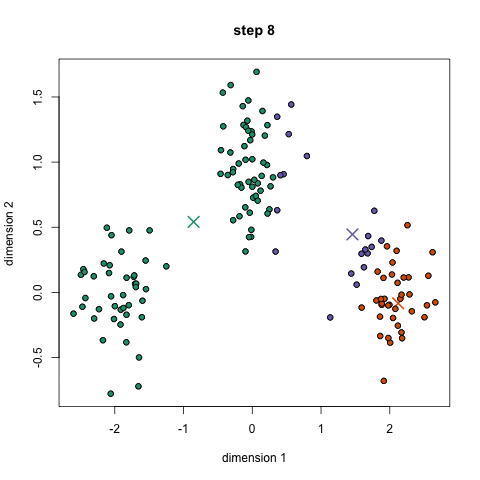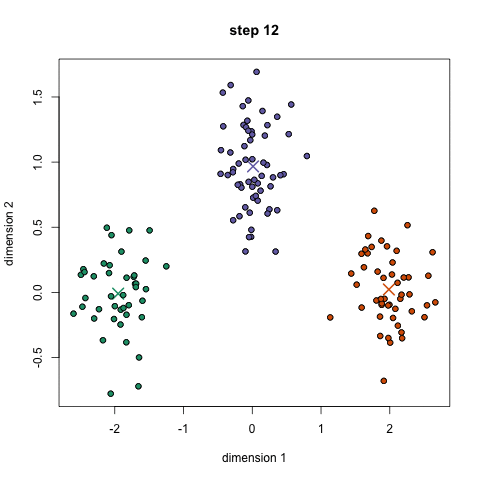
The 5 Clustering Algorithms Data Scientists Need To Know By George Seif Towards Data Science

Exploring Clustering Algorithms Explanation And Use Cases Neptune Ai
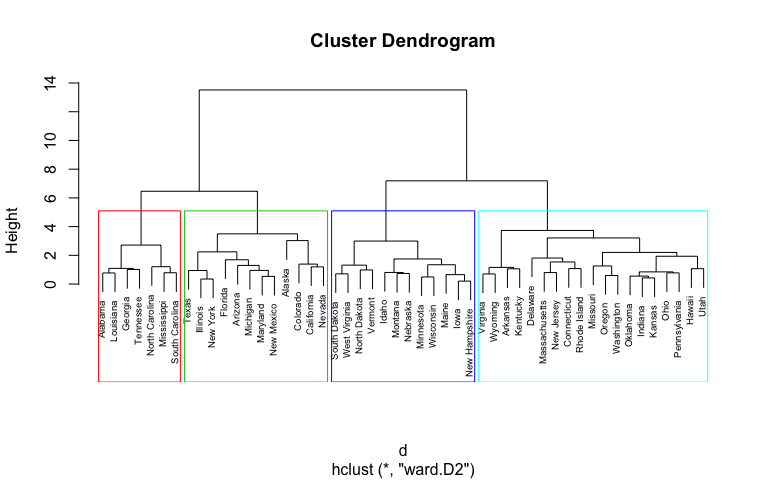
Hierarchical Cluster Analysis Uc Business Analytics R Programming Guide

Exploring Clustering Algorithms Explanation And Use Cases Neptune Ai
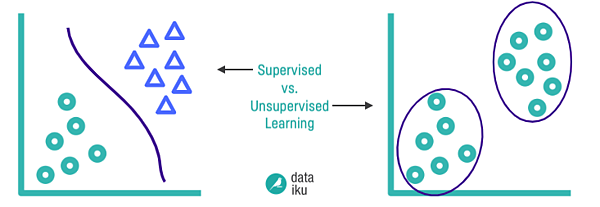
Clustering How It Works In Plain English
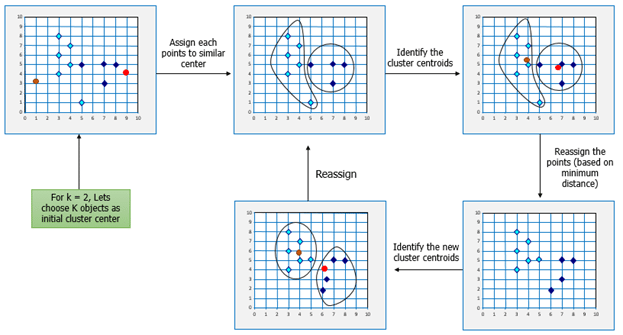
Understanding K Means Clustering With Examples Edureka
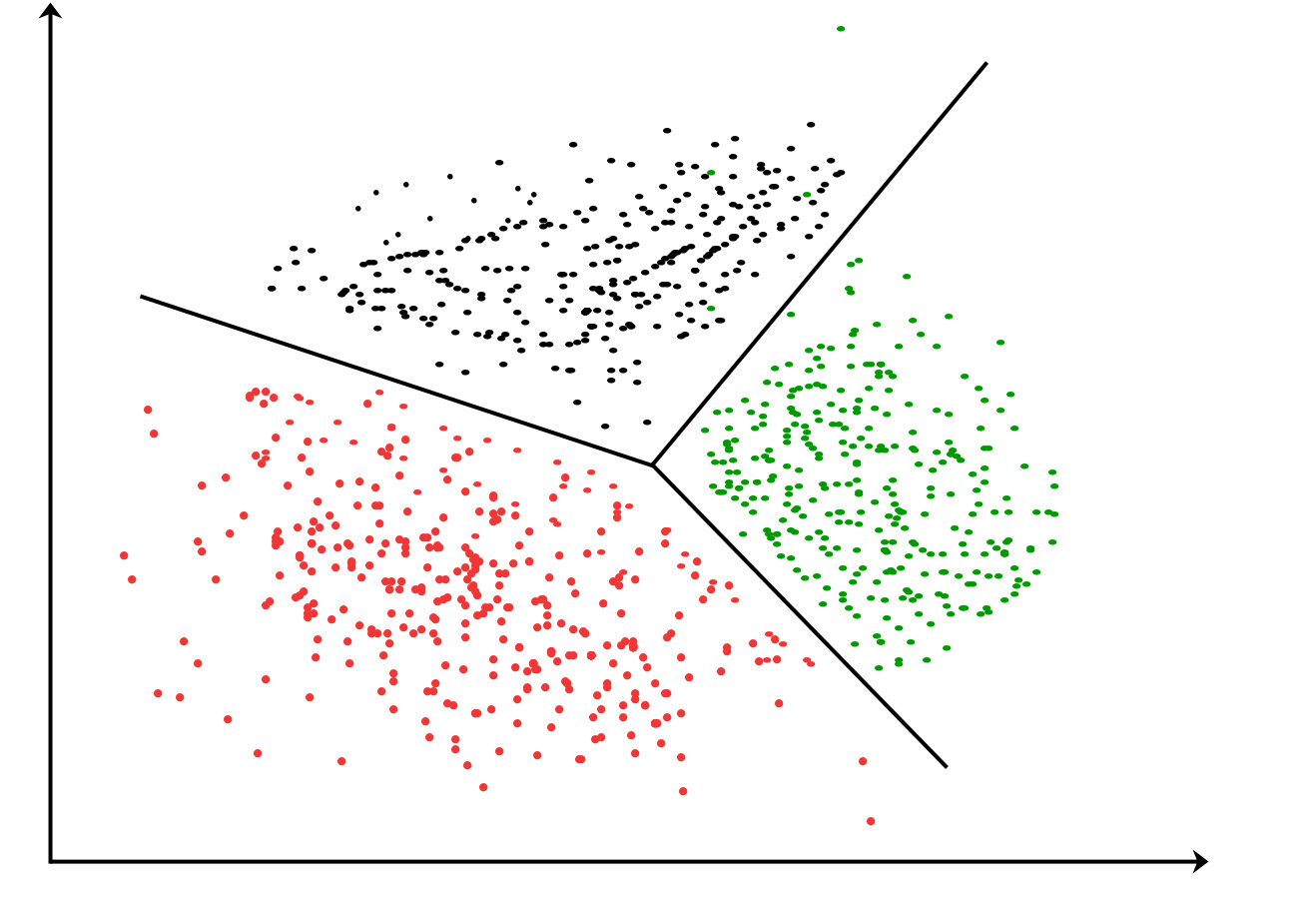
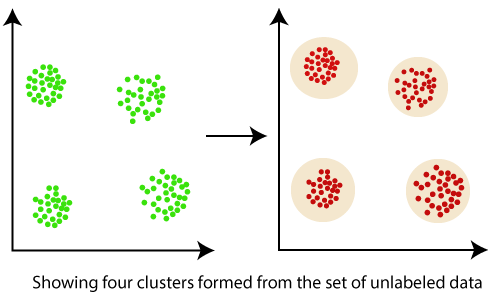
Clustering In Machine Learning Geeksforgeeks

Exploring Clustering Algorithms Explanation And Use Cases Neptune Ai

Similarity Measure Machine Learning Data Science Glossary Machine Learning Data Science Machine Learning Methods
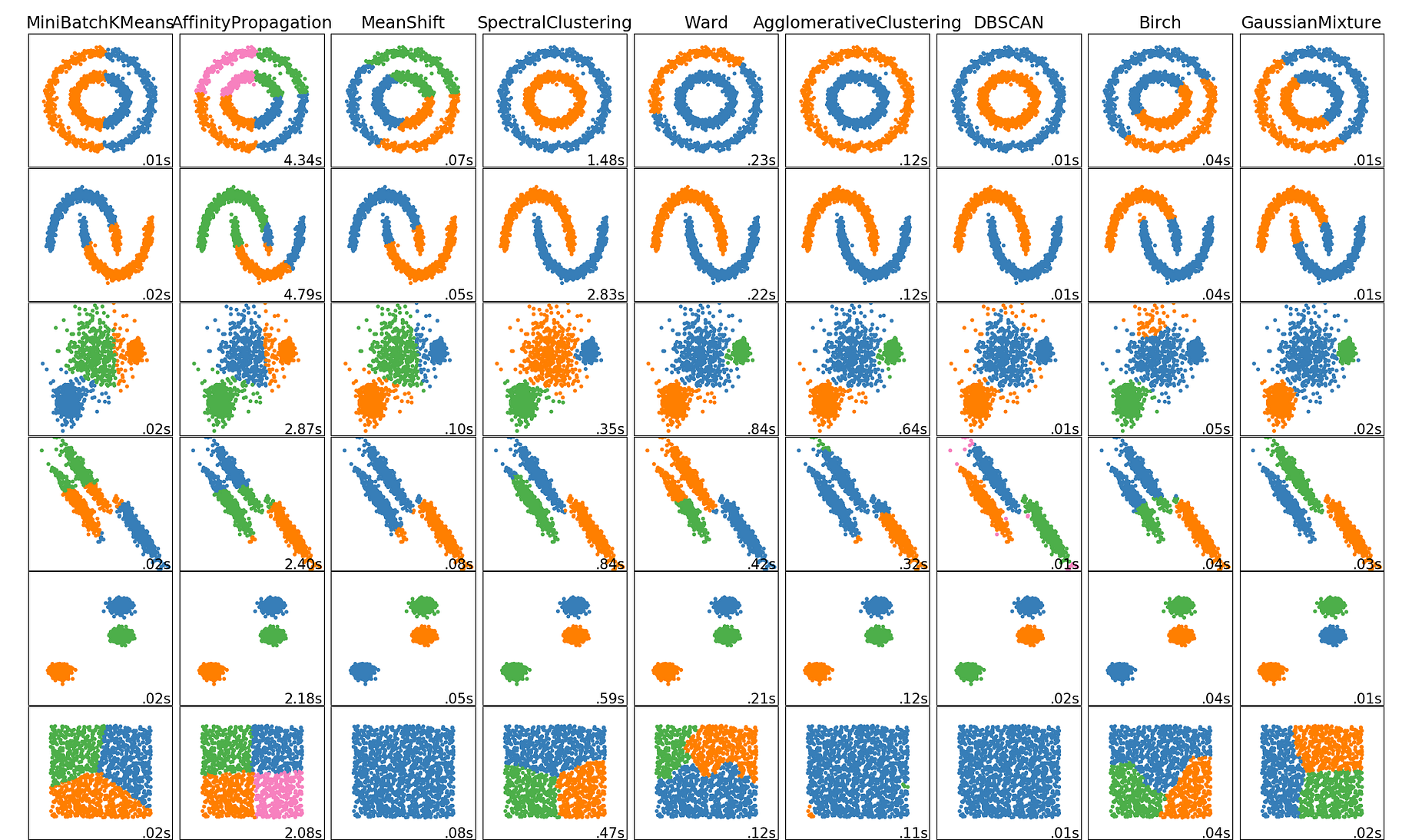
The 5 Clustering Algorithms Data Scientists Need To Know By George Seif Towards Data Science
Clustering In Machine Learning Geeksforgeeks
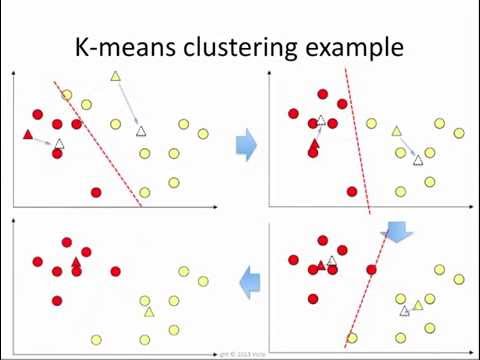
K Means Clustering How It Works Youtube
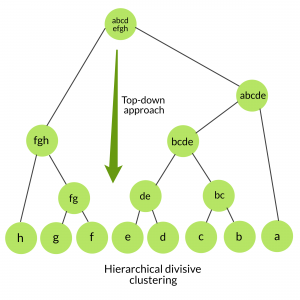
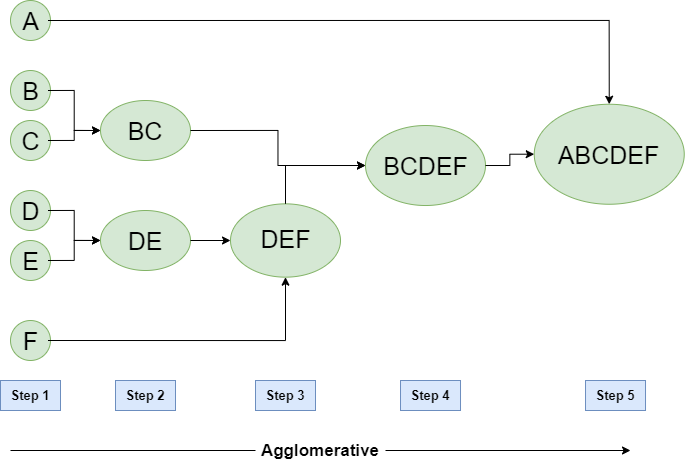
Ml Hierarchical Clustering Agglomerative And Divisive Clustering Geeksforgeeks



Comments
Post a Comment